https://www.acmicpc.net/problem/11585
11585번: 속타는 저녁 메뉴
수원이와 친구들은 저녁 메뉴를 잘 선택하지 못한다. 배가 고픈 수원이가 보다 못해 메뉴를 정하곤 하는데 이마저도 반대에 부딪히는 경우에는 수원이가 원형 룰렛을 돌려 결정하곤 한다. 이 원
www.acmicpc.net


- 알고리즘 : KMP
- 풀이 날짜 : 2023.07.07.
< 풀이 설명 >
KMP(Knuth Morris Partt Algorithm) 알고리즘을 공부한 문제이다.
기준 문자열(text, 길이 N) 과 그 안에서 찾고자 하는 문자열(pattern, 길이 M) 을 효율적으로 비교하는 알고리즘이다.
무릇 두 문자열을 비교할 때 하나하나씩 비교하면 되는데 (브루트 포스), 시간복잡도가 O(N * M) 이 나온다.
하지만 KMP 알고리즘을 사용하면, 시간 복잡도를 O(N + M) 까지 줄일 수 있다.
이 문제 풀이 자체는 간단하다.
회전하는 문자열을 1차원 행렬로 다루기 위해 똑같은 문자열을 뒤에 붙여주는 것은
초 / 중학교 때 수학 문제에서 많이 사용하던 방식이다 (N + N - 1 : 동일한 문자열 제외).
백준 5525번 문제에서는 반복되는 문자열이 정해져 있어, 비교한 부분을 스킵한다는 생각을 자연스럽게 차용하여 풀었다.
ptr = I O I
O O I O I O I I O I I
O O I O I O I I O I I
https://www.acmicpc.net/problem/5525
5525번: IOIOI
N+1개의 I와 N개의 O로 이루어져 있으면, I와 O이 교대로 나오는 문자열을 PN이라고 한다. P1 IOI P2 IOIOI P3 IOIOIOI PN IOIOI...OI (O가 N개) I와 O로만 이루어진 문자열 S와 정수 N이 주어졌을 때, S안에 PN이 몇
www.acmicpc.net
import java.io.*;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
Character[] ptr = new Character[2 * n + 1];
int ptrlen = ptr.length;
for (int i = 0; i < ptrlen - 1; i++) {
if (i % 2 == 0) ptr[i] = 'I';
else ptr[i] = 'O';
}
ptr[ptrlen - 1] = 'I';
int m = Integer.parseInt(br.readLine());
String text = br.readLine();
//for (int i = 0; i < m; i++) Character[] ptr[i] = text.charAt(i);
int result = 0, j = 0;
for (int i = 0; i < m; i++) {
if (ptr[j] == text.charAt(i)) { // 일치
if (++j == ptrlen) {
j = ptrlen - 2;
result++;
}
} else { // 불일치
j = 0;
/*
IOI'I'OI 일 때, 4번째 I에서 무시하면 안 됨. 새 시작점이 될 수 있다.
I'O'I
'I'OI
그럼, OOIO일 때 처음에서 계속 iteration 도는데, 처리는?
*/
//if (ptr[j] == text.charAt(i)) i--;
if (text.charAt(i) == 'I') i--;
}
}
bw.write(result + "\n");
br.close();
bw.flush();
bw.close();
}
}import java.io.*;
import java.util.StringTokenizer;
public class Test {
static int n, m;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
n = Integer.parseInt(st.nextToken());
Character[] ptr = new Character[2 * n + 1];
int ptrlen = ptr.length;
for (int i = 0; i < ptrlen - 1; i++) {
if (i % 2 == 0) ptr[i] = 'I';
else ptr[i] = 'O';
}
ptr[ptrlen - 1] = 'I';
m = Integer.parseInt(br.readLine());
String text = br.readLine();
//for (int i = 0; i < m; i++) Character[] ptr[i] = text.charAt(i);
bw.write(findCount(ptr, text) + "\n");
br.close();
bw.flush();
bw.close();
}
static int findCount(Character[] ptr, String text) {
int ptrlen = ptr.length;
int result = 0, j = 0;
for (int i = 0; i < m; i++) {
while (ptr[j] == text.charAt(i)) { // 일치
if (++j == ptrlen) {
j = ptrlen - 2;
result++;
}
if (++i == m) return result; /** StringIndexOutOfBounds 조심 **/
}
// 불일치
j = 0;
/*
IOI'I'OI 일 때, 4번째 I에서 무시하면 안 됨. 새 시작점이 될 수 있다.
I'O'I
'I'OI
그럼, OOIO일 때 처음에서 계속 iteration 도는데, 처리는?
*/
//if (ptr[j] == text.charAt(i)) i--;
if (text.charAt(i) == 'I') i--;
}
return result;
}
}import java.io.*;
import java.util.StringTokenizer;
public class Test {
static int n, m;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
n = Integer.parseInt(st.nextToken());
Character[] ptr = new Character[2 * n + 1];
int ptrlen = ptr.length;
for (int i = 0; i < ptrlen - 1; i++) {
if (i % 2 == 0) ptr[i] = 'I';
else ptr[i] = 'O';
}
ptr[ptrlen - 1] = 'I';
m = Integer.parseInt(br.readLine());
String text = br.readLine();
//for (int i = 0; i < m; i++) Character[] ptr[i] = text.charAt(i);
bw.write(findCount(ptr, text) + "\n");
br.close();
bw.flush();
bw.close();
}
static int findCount(Character[] ptr, String text) {
int ptrlen = ptr.length;
int result = 0, j = 0;
for (int i = 0; i < m; i++) {
while (i < m && ptr[j] != text.charAt(i)) { /* (++i) */
j = 0; // 불일치 -> 첨부터 다시 (일치할 때까지)
i++;
if (text.charAt(i - 1) == 'I') i--; /** IOIIOI 예외 **/
}
// 일치
if (++j == ptrlen) {
j = ptrlen - 2;
result++;
}
}
return result;
}
}
이 아이디어를 차용한 알고리즘이 KMP이다.
간단한 원리는 다음과 같다.
기준 문자열이 ABABDABABC 이고 찾아야 하는 문자열이 ABABC 일 때,
D와 C가 맞지 않아 ABABC를 움직여 주어야 한다.
이때 우리는 자연스럽게 다음과 같이 이동해준다.
A B A B D A B A B C
===================
A B A B C
→ → A B A B C
KMP를 수행해 보자.
먼저 찾고자 하는 패턴 문자열인 ptr에 대한 table 배열을 생성한다.
Table 배열의 정의는, 문자열 처음부터 일치하는 문자 개수 이다.
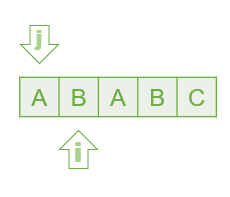
문자열의 처음부터 일치하는 문자를 가리키는 포인터 j 와, 문자열을 탐색하는 포인터 i 를 이용한다.
문자열의 j 번째와 i 번째 문자가 일치하면 같이 1씩 증가시킨다.
불일치할 때 처리를 잘 해주어야 하는데, 우리가 생성하는 table의 정의를 잘 생각해야 한다.
Table 배열에는 `첫 문자부터 해당 인덱스까지 일치하는 문자 개수 == 체크할 다음 인덱스` 를 저장한다.
예를 들어 처음부터 시작한 'ABABAB' 와 3번째 문자인 'A' 부터 시작한 'ABABAB' 가 일치하고 있었는데,
9번째인 문자 'C' 에서 불일치가 일어났다.
3번째 문자부터 시작한 문자열은 실패했으므로, 바로 앞 문자 'B' 를 포함하는 새로운 문자열을 찾아야한다.
그 지점부터 다시 맞춰줄 수 있기 때문이다.
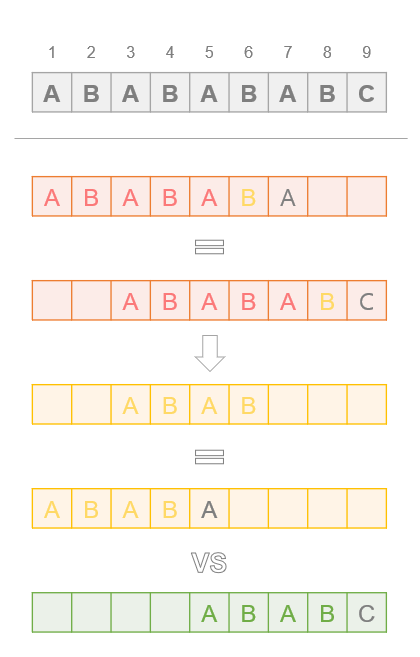
8번째 문자인 'B' 는, 처음 문자부터 6번째 문자인 'B' 까지 일치했다.
그럼 6번째 문자인 'B' 는, 처음 문자부터 4번째 문자인 'B' 까지 일치했음을 알 수 있다.
처음부터 시작한 'ABABAB' 와 3번째 문자부터 시작한 'ABABAB' 가 일치하고 있었는데,
"처음부터 시작한 'ABAB' 와 5번째 문자부터 시작한 'ABAB' 가 일치하고 있었는데" 로 바꿔서 다시 시작하는 것이다.
트리에서 부모와 조부모를 탐색하는 것과 비슷하다.
static void setTable() { // table = 처음부터 일치하는 길이(다음 인덱스)
// j = 움직(앞), i = 기준
int j = 0;
for (int i = 1; i < ptr.length(); i++) {
// 불일치(일치할 때까지 or i = 0까지)
// AB AB AB AB C
// AB AB AB AB C (B가 포함된 새로운 시작점 찾아야함 == table값)
// 00 12 34 56 0
// AB AB AB AB C
// AB AB AB AB C
// 만약 반복되는 패턴이 없으면, j = 0까지 돌아갈거임
while (j > 0 && ptr.charAt(i) != ptr.charAt(j)) /** j == 0 무한루프 **/
j = table[j - 1];
// 일치할 때
if (ptr.charAt(i) == ptr.charAt(j))
table[i] = ++j;
}
}
// ABD ABC ABD
// 000 120 123
// ABC ABC
// 000 120
// ABC ABC ABD
// 000 123 450
이제 문자열에서 패턴이 존재하는지(혹은 몇 개인지) 찾아야한다.
Table을 생성할 때와 원리는 비슷하지만 조금 다르다.

위 예제에서 5번째 문자에서 불일치가 일어났다.
그 전까지는 일치했다는 뜻이므로, 4번째 문자열의 table을 살핀다.
table 배열은 `첫 문자부터 일치한 문자 개수` 이기 때문이다.
인덱스 j 를, 현재의 j 의 table [j - 1] 값으로 변경해주어 패턴이 옮겨간 것처럼 효과를 준다.
즉, 일치여부를 확인한 부분을 다시 확인을 하지 않는 것이다.
static void kmp(String txt, String ptr) {
int txtlen = txt.length();
int ptrlen = ptr.length();
int j = 0; // 현재 대응되는 글자 수
for (int i = 0; i < txtlen; i++) {
while (j > 0 && txt.charAt(i) != ptr.charAt(j))
j = table[j - 1];
if (txt.charAt(i) == ptr.charAt(j)) {
// 패턴의 끝까지 확인했으면 정답
// IIOII OIO
// IIOII (I를 포함하는 새로운 문자열)
// 01012
// II(OII)
if (j == ptrlen - 1) break; // j = table[j]; count++;
else j++;
}
}
}
인덱스와, 내가 다음에 취해야 할 stance가 무엇인지 차근차근 생각하면 너무나 자명하고 유용한 알고리즘이다.
다음 문제로 기본적인 KMP를 연습해볼 수 있다. 물론 브루트 포스로 풀어도 되는 문제이긴 하다.
https://www.acmicpc.net/problem/16916
16916번: 부분 문자열
첫째 줄에 문자열 S, 둘째 줄에 문자열 P가 주어진다. 두 문자열은 빈 문자열이 아니며, 길이는 100만을 넘지 않는다. 또, 알파벳 소문자로만 이루어져 있다.
www.acmicpc.net
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
public static int[] table;
public static String all, ptr;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
all = br.readLine();
ptr = br.readLine();
table = new int[ptr.length()];
setTable();
System.out.println(KMP());
}
public static void setTable() {
int j = 0;
for (int i = 1; i < ptr.length(); i++) {
while (j > 0 && ptr.charAt(i) != ptr.charAt(j))
j = table[j - 1];
if (ptr.charAt(i) == ptr.charAt(j))
table[i] = ++j;
}
}
public static int KMP() {
int j = 0;
for (int i = 0; i < all.length(); i++) {
while (j > 0 && all.charAt(i) != ptr.charAt(j))
j = table[j - 1];
if (all.charAt(i) == ptr.charAt(j)) {
if (j == ptr.length() - 1) return 1;
else j++;
}
}
return 0;
}
}
< 筆者의 辯 >
기약분수로 나타내라 하면 최대공약수를 구하는 유클리드 호제법을 이용한다.
하지만 해당 문제는 그러지 않아도 된다.
분자가 분모로 나누어 떨어지는 경우만 있기 때문이다.
이유는 간단하다.
돌림판이기 때문에 이를 1차원적으로 생각하려면 문자열을 2번 이어붙여 주어야 한다.
여기서 찾고자 하는 문자열을 여러 개 찾을 수 있다면, 패턴 문자열 길이의 약수 만큼 일 것이다.
다음 초록색 덩어리를 ABC 라고 가정하자.
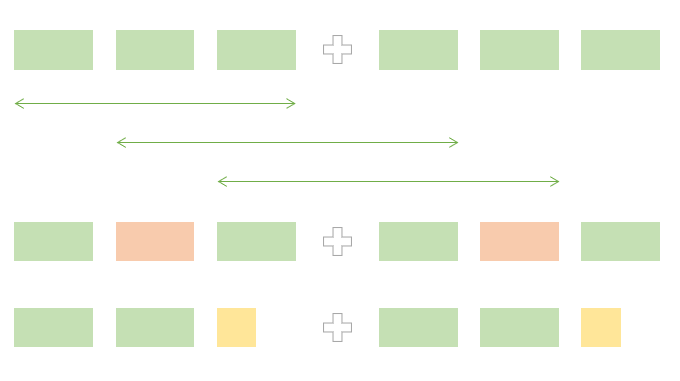
위 그림의 두번째 줄 처럼 중간에 다른 문자열이 들어가면 안되고
마지막 줄처럼 마지막에 하나라도 다른 문자가 들어가면 안된다.
따라서 문자열 내에서 반복이 되는 기준 문자열이 존재한다면,
이는 문자열 길이의 약수 길이일 것이므로, 답은 항상 분자가 1로 고정이다.
이 원리를 이용하여 table을 '여태까지 맞은 문자 개수' 라고 정의하여
다음 문제처럼 풀 수도 있다.
[백준/KMP] - 백준 1305: 광고 [플래티넘 Ⅳ / JAVA]
반복되는 기준이 되는 문자열 길이만 뺀 나머지 값이 나올 것이다.
ABC ABC + ABC ABC
000 123 456 789
2 * 6 - 9 = 3
두 가지 풀이는 다른 사람의 풀이를 보고 더 공부한 것이다.
하지만 이런 관통하는 특징까지 과연 문제를 처음 접할 때 생각할 수 있을까? 의문이 든다.
< 코드 >
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
static int n;
public static int[] table;
public static String text, ptr;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
n = Integer.parseInt(br.readLine());
ptr = br.readLine().replaceAll(" ", "");
char[] tmp = br.readLine().replaceAll(" ", "").toCharArray();
char[] txt = new char[2 * n - 1];
for (int i = 0; i < 2 * n - 1; i++) txt[i] = tmp[i % n];
text = String.valueOf(txt);
table = new int[n];
setTable();
int result = kmp();
StringBuilder sb = new StringBuilder();
// int divisor = gcd(n, result);
// sb.append(result / divisor);
// sb.append('/');
// sb.append(n / divisor);
sb.append("1/" + n / result);
System.out.print(sb);
}
public static void setTable() {
int j = 0;
// j: 움직(앞), i: 기준(뒤)
for (int i = 1; i < ptr.length(); i++) {
while (j > 0 && ptr.charAt(i) != ptr.charAt(j))
j = table[j - 1];
if (ptr.charAt(i) == ptr.charAt(j))
table[i] = ++j;
}
}
public static int kmp() {
int count = 0;
int j = 0;
for (int i = 0; i < text.length(); i++) {
while (j > 0 && text.charAt(i) != ptr.charAt(j))
j = table[j - 1];
if (text.charAt(i) == ptr.charAt(j)) {
if (j == ptr.length() - 1) {
count++;
j = table[j];
} else j++;
}
}
return count;
}
static int gcd(int a, int b) {
if (b == 0) return a;
return gcd(b, a % b);
}
}
'Algorithm > KMP' 카테고리의 다른 글
| 백준 1305: 광고 [플래티넘 Ⅳ / JAVA] (0) | 2023.07.17 |
|---|---|
| 백준 1786: 찾기 [플래티넘 Ⅴ / JAVA] (0) | 2023.07.17 |